

@misc{abid2025robustlabelefficientdeepwaste,
title = {Robust and Label-Efficient Deep Waste Detection},
author = {Hassan Abid and Khan Muhammad and Muhammad Haris Khan},
year = {2025},
eprint = {2508.18799},
archivePrefix = {arXiv},
primaryClass = {cs.CV},
url = {https://arxiv.org/abs/2508.18799}
}Zero-Shot OVOD
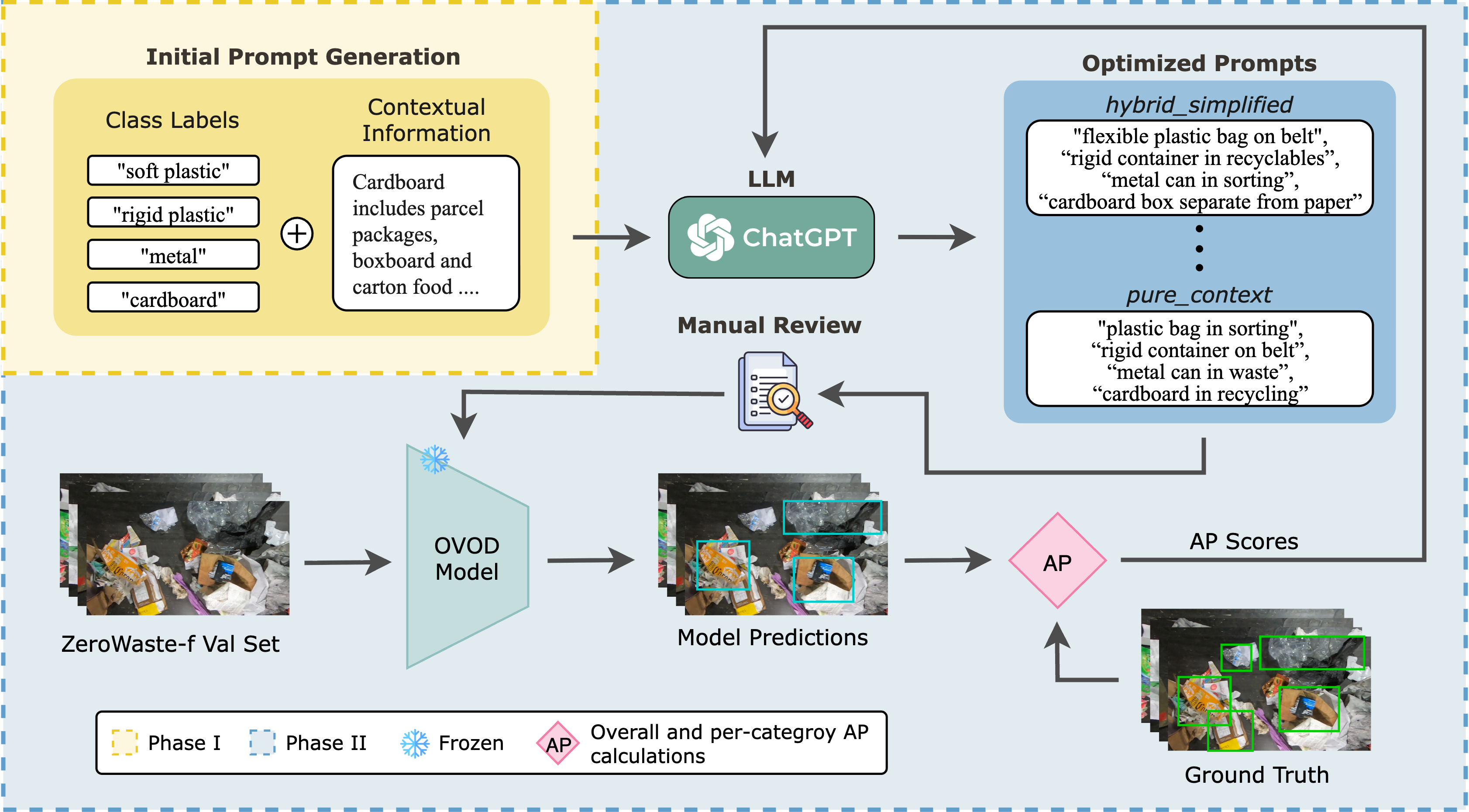
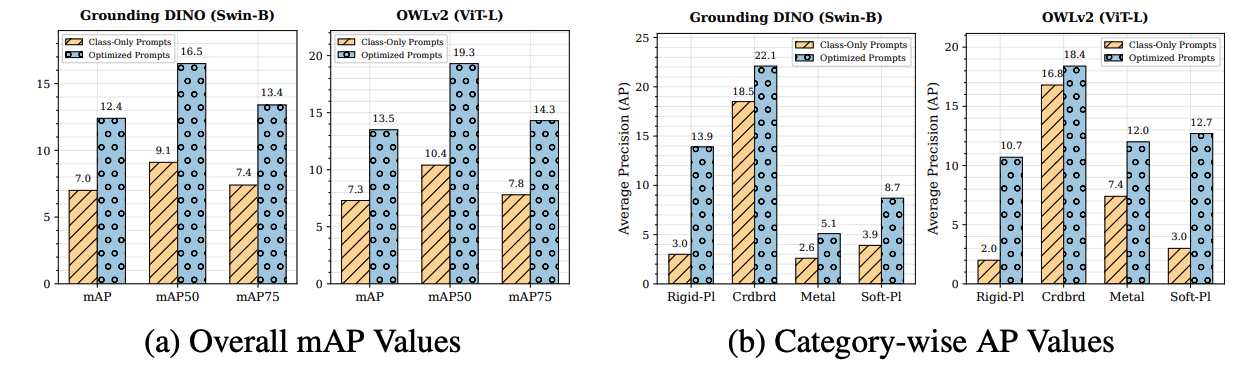
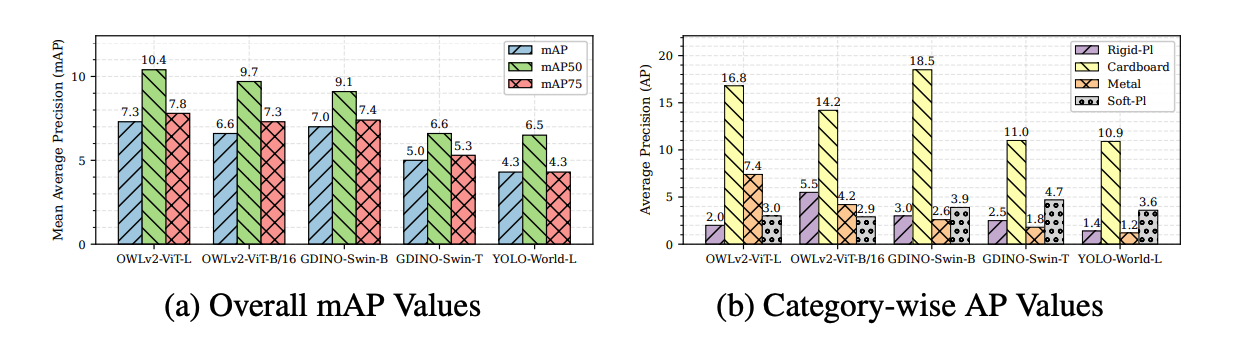
We benchmark Grounding DINO, OWLv2, and YOLO-World in a zero-shot setting on ZeroWaste using only class-level prompts (“cardboard”, “soft plastic”, “rigid plastic”, “metal”). Performance is uniformly low (mAP ≤ 7.3), with large objects detected more reliably than transparent or reflective ones.
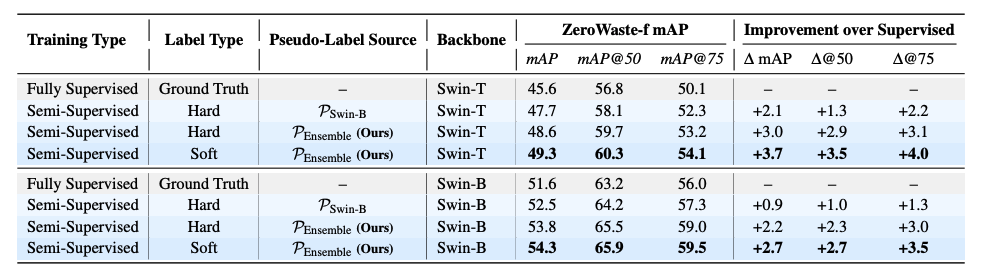
To improve results, we introduce an LLM-guided prompt optimization pipeline, where GPT-4o enriches class names with contextual cues (e.g., “flexible plastic bag”). This yields consistent gains—OWLv2 +6.2 mAP, Grounding DINO +5.4—yet still trails supervised baselines, underscoring the need for domain adaptation.